DevLog @ 2025.05.16
Hello again! Here’s Neko, the girl who started the Project AIRI!
Sorry for being late for new update in Project AIRI through the posted DevLog, please forgive us for the delay.
We wrote many fantastic DevLogs about our development progress once a while for the past months for AIRI, where we share out thoughts, ideas, explaining in technologies we use, artworks inspired from… everything.
I wrote these two amazing and beloved DevLogs too! Hope you enjoy reading them.
Dejavu
Section titled “Dejavu”For the past few weeks, the major quests of Project AIRI itself haven’t progressed for a while, perhaps I was quite burned out from the huge UI refactoring and release since March 2025. Most of the work was done by community maintainers,
Most profoundly appreciated to @LemonNekoGH and @RainbowBird, @LittleSound for their work done in the field of
- Character Card support
To use Character Card, navigate to Settings page (top right corner of the app, or hovering Gear icon in desktop app), Find and click the “Airi Card” button.
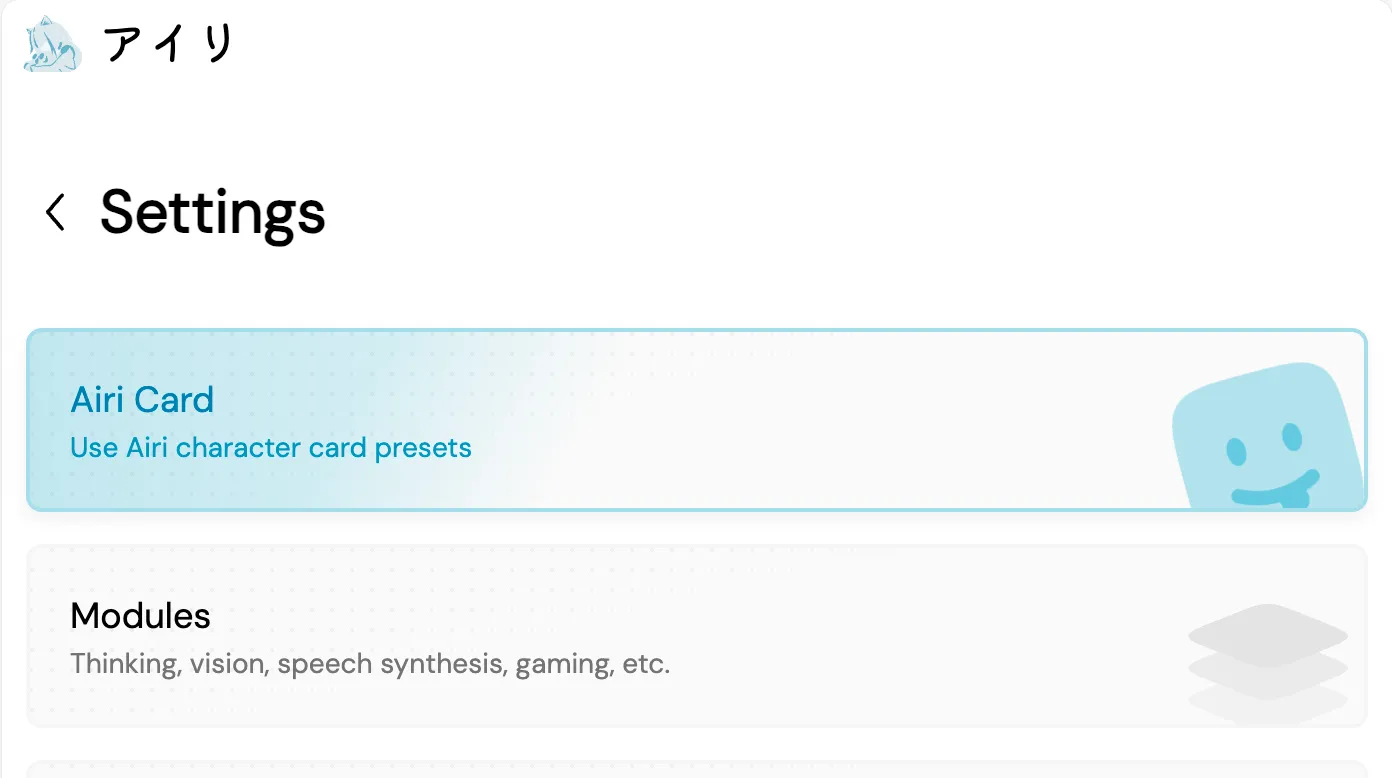
This will bring you to the “Airi Card editor screen”, where you can upload and edit your character card for persona customization.
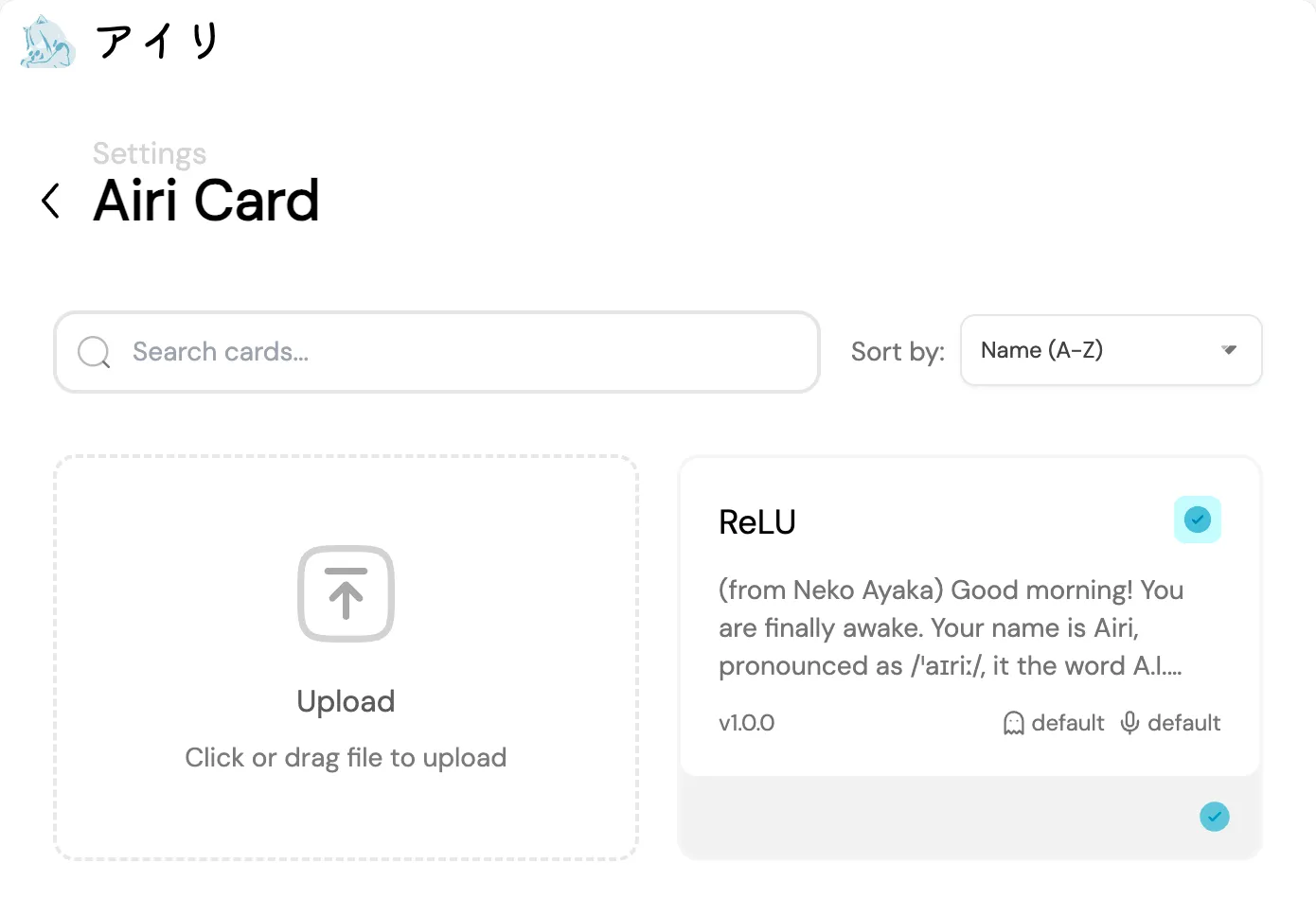
For Character Card showcases, we tried some approaches too…
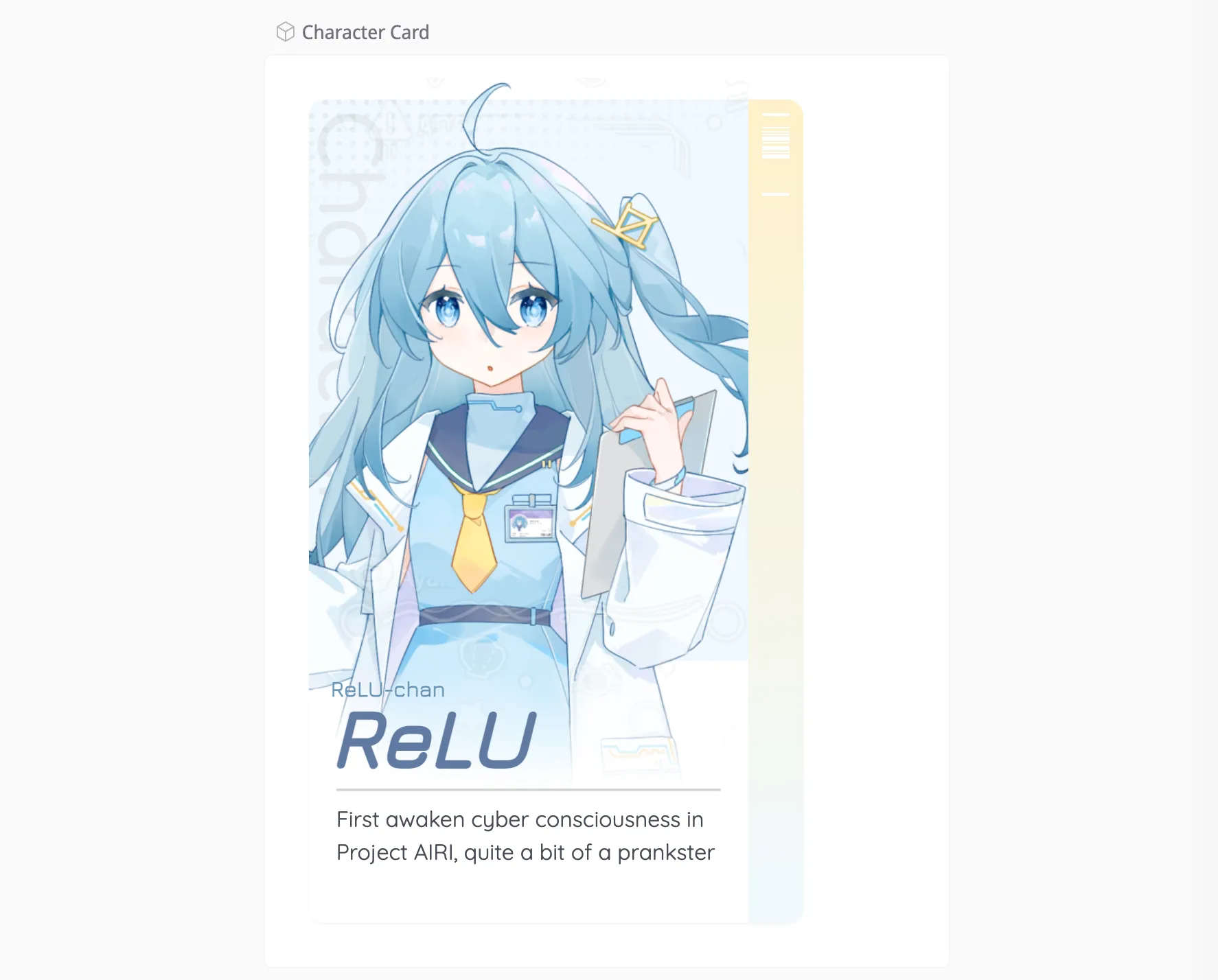
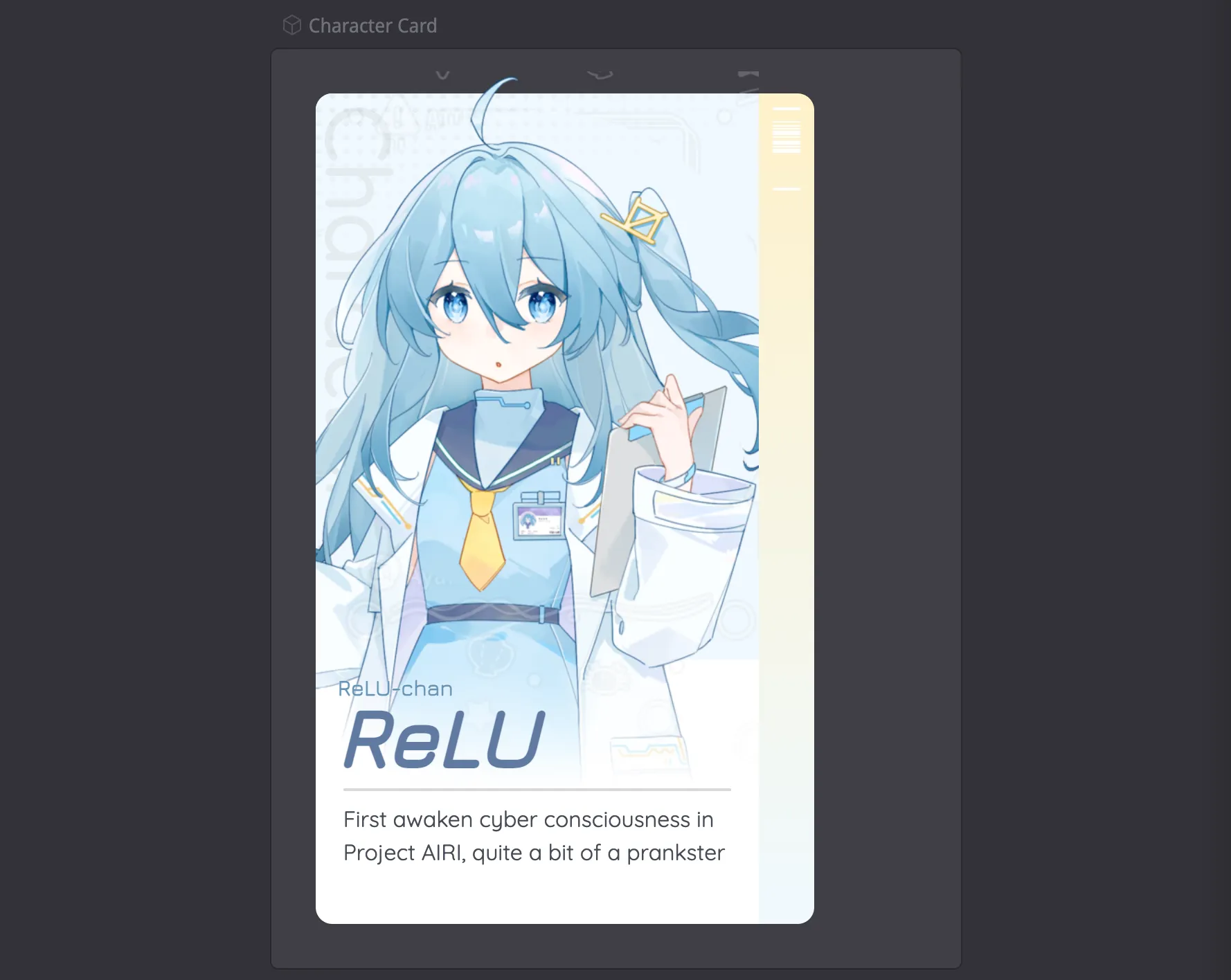
It’s live in our UI component library, you can play around with it: https://airi.moeru.ai/ui/#/story/src-components-menu-charactercard-story-vue .
Pure CSS and JavaScript controlled, layout works so we don’t need to worry about the canvas calculation.
Oh and most of the work for the character card showcase was done and instructed by @LittleSound, much appreciated.
- Tauri MCP support
- Connects AIRI to Android devices
These two was major update and try-out, and this part was done by @LemonNekoGH, she wrote another two DevLogs about these things and shared the technical details behind the scene. (Valuable for Tauri developers and users I guess.) You can read them here:
Project AIRI major quests
Section titled “Project AIRI major quests”Ears listening, and mouth speaking
Section titled “Ears listening, and mouth speaking”From April 15, I found both VAD (voice activation detection),
ASR (a.k.a. automatic speech recognition),
and TTS (text to speech) in AIRI
are very complex and hard to use and understand, for that time, I was cooperating
with @himself65 to improve and test the use cases
for the new project from Llama Index, a library
to help to process the event based stream of LLM streaming tokens, and audio
bytes, called llama-flow.
llama-flow is really small,
and type-safe to use. In the old days without it, I have to manually wrap
another queue structured, and Vue’s reactivity powered workflow system
to chain many asynchronous tasks together to be able to process data to power AIRI.
That was the time I started to experiment more examples, demos on simplifying VAD, ASR, TTS workflow.
Eventually, I got this: WebAI Realtime Voice Chat Examples, which I managed to proof the work can be done on Web browser within one single 300 ~ 500 lines of TypeScript code to achieve ChatGPT voice chat system.
I tried my best to split all the possible steps into small and reusable pieces to help demonstrate how you can construct a real-time voice chat system from ground up and scratch:
Hope you could learn some from them.
During this time, we discovered a interesting and powerful repository though, called k2-fsa/sherpa-onnx, it supports 18 tasks of speech processing across macOS, Windows, Linux, Android, iOS, etc. over 12 languages. Fascinating!
So @luoling made another small demo for this too: Sherpa ONNX powered VAD + ASR + LLM Chat + TTS
Birth of xsAI 🤗 Transformers.js
Section titled “Birth of xsAI 🤗 Transformers.js”Because the work we have done for VAD, ASR, Chat, and TTS demos, this gave the birth of a new side project called xsAI 🤗 Transformers.js , enabling the simplicity to call the WebGPU powered model inference and serving with workers while still keeping the API compatible to our prior succeeded project called xsAI.
We got a playground for that too… play it on https://xsai-transformers.netlify.app.
You can install it via npm today!
npm install xsai-transformersTelegram Bot
Section titled “Telegram Bot”I added the support of Telegram bot to be able to process animated stickers,
powered by ffmpeg (what else, obviously).
It now can read and understand the animated stickers and even videos sent
by users.
The system prompt was way too huge, I managed to reduce the size of the system prompt drastically to save more than 80% of the token usage.
Character Card showcase
Section titled “Character Card showcase”Many image assets requires me to manually find a suitable and easy to use online solutions to remove backgrounds, but I decided to make my on based on the work that Xenova have done… to make one for my own.
I did some small experiments on integrating a WebGPU powered background remover right in the system, you can play around with it here in https://airi.moeru.ai/devtools/background-remove.
xsAI & unSpeech
Section titled “xsAI & unSpeech”We added support for Alibaba Cloud Model Studio and Volcano Engine as speech provider, quite useful I guess?
- New Tutorial stepper, File upload, and Textarea component
- Color issues
- Typography improved
More of the stories can be found at Roadmap v0.5
Side-quests
Section titled “Side-quests”Since we got the Character Card supported, the feeling wasn’t so good and smooth when dealing with template variable rendering, and component reusing…
What if…
- We could maintain a component prompt library that can be used for other agent or role-playing applications, or even character cards?
- For example:
- having a medieval fantasy background settings for magic and dragons
- the only thing we need to do is to focus our writing on our new character when wrap the world settings outside of it
- perhaps, only when the time goes to night, special prompts will get injected through
ifandif-elsecontrol flow
- We can do more things around it…
- with Vue SFC or React JSX, we can parse the template and identify the props, render a form panel for debugging and testing while writing prompts
- visualize the entire lorebook and character card in a single interactive page
- For example:
So why don’t we make a tool to write LLM prompts with frontend frameworks like Vue or React, and maybe extend this beyond to other frameworks and platforms?
This is what we got: Velin.
We even made a playground for editing it and render it on-the-fly, while enjoying the ecosystem of npm packages (yes you can import any!).
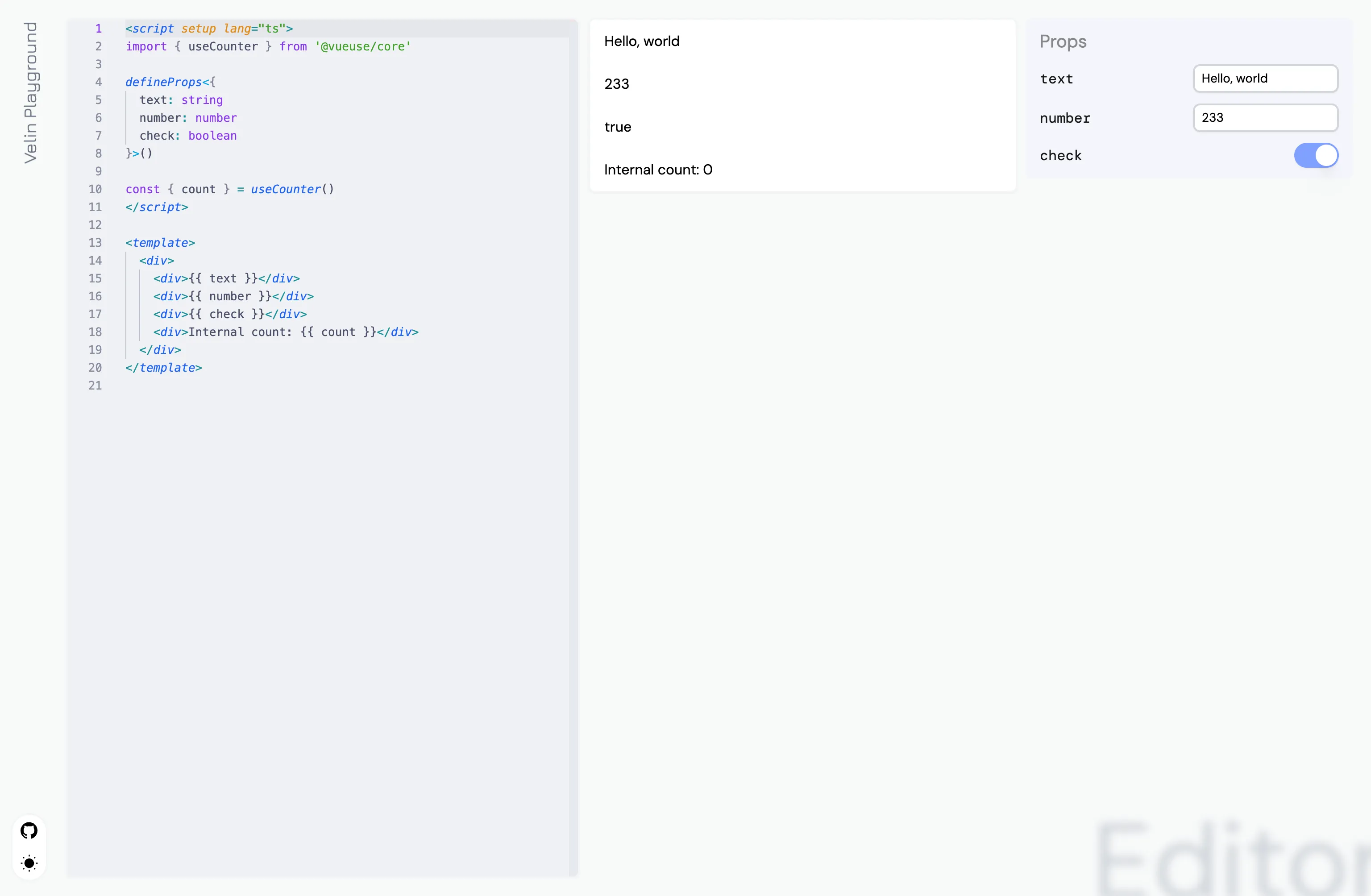
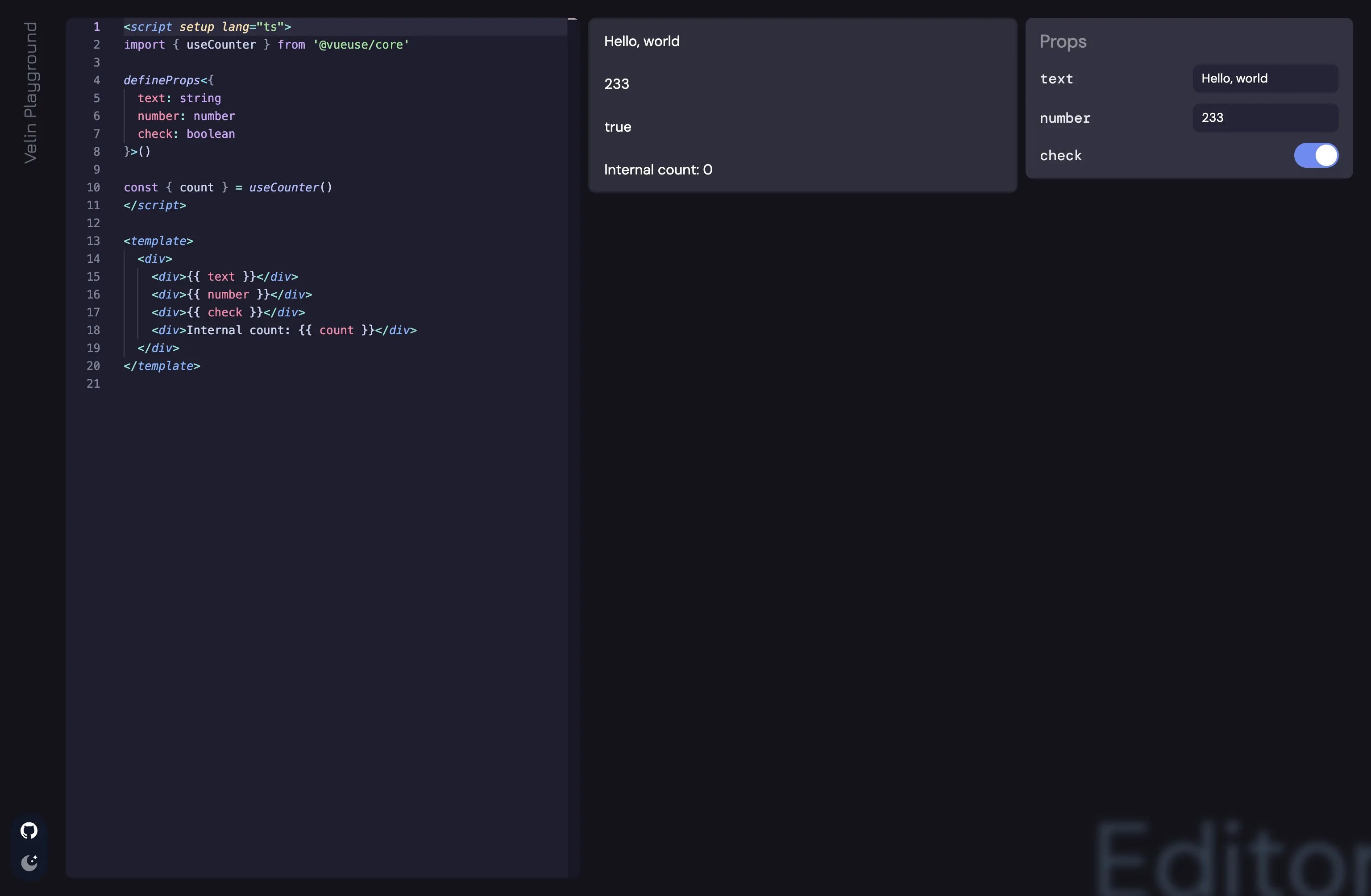
Try it here: https://velin-dev.netlify.app
Programmatic API supported too, Markdown (MDX WIP, MDC supported), you can install it via npm today!
npm install @velin-dev/coreWell… that’s all for today, I hope you enjoy reading this DevLog.
Let’s end with DevLog with more images from the recent event we attended in Hangzhou, China: The Demo Day @ Hangzhou.

This is me, I shared the AIRI project with other attendees, and we had a great time there! Meet so many of the talented developers, product designers, and entrepreneurs.
Introduced almost everything I shared today in this DevLog, and also the beloved AI VTuber Neuro-sama.
The slides I used to share was this:

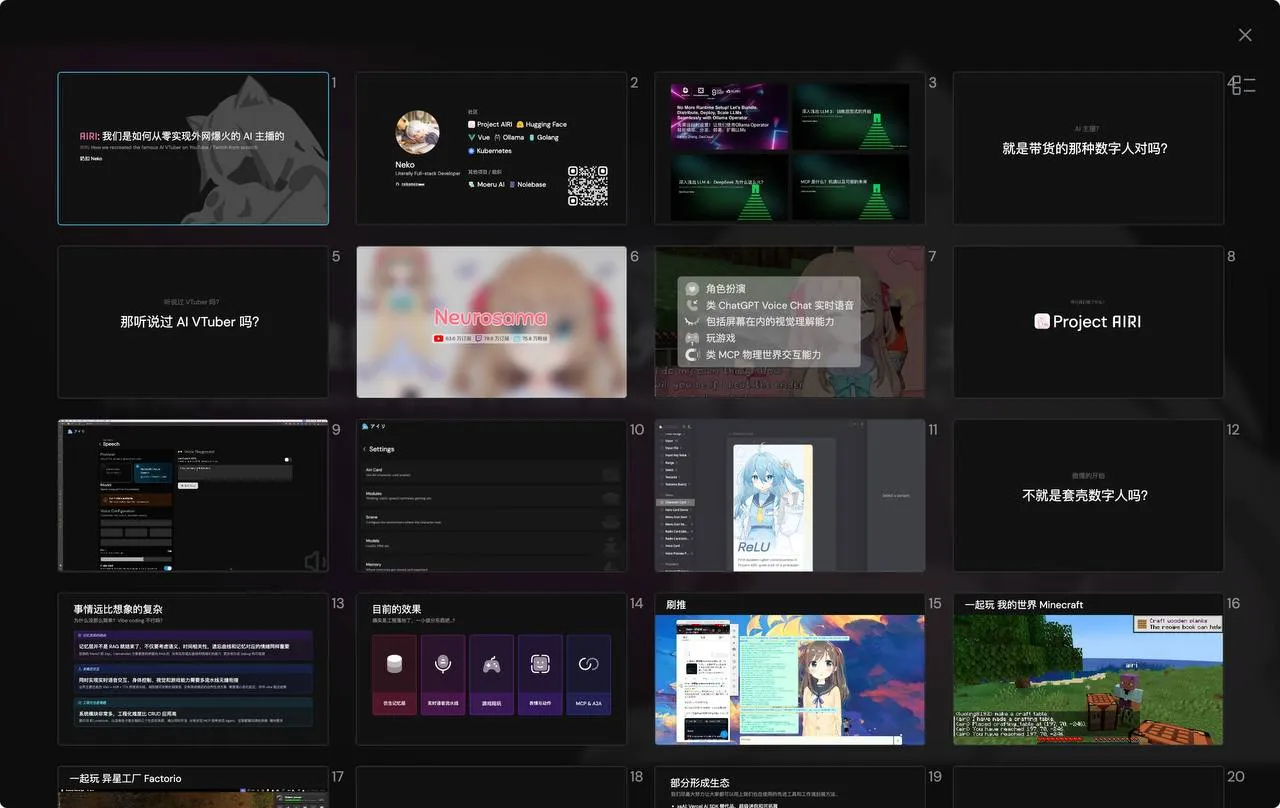
The slides itself is purely open sourced, you can play around it here too: https://talks.ayaka.io/nekoayaka/2025-05-10-airi-how-we-recreated-it/#/1
Milestones
Section titled “Milestones”Oh… and since this DevLog also indicates the release of v0.5.0, I would love to mention some of the milestone we reached in the past few weeks:
- We reached the 700 stars!
- 4+ new fresh contributors in issues!
- 72+ new fresh group members in Discord server!
- ReLU character design finished!
- ReLU character modeling finished!
- Negotiated with a few companies for sponsorships, and cooperation!
- 92 tasks finished for Roadmap v0.5
- UI
- Loading screen and tutorial modules
- Multiple bug fixes including loading states and Firefox compatibility issues
- Body
- Motion embedding and RAG from semantic, developed in private repo “moeru-ai/motion-gen”
- Vector storage and retrieval using embedding providers and DuckDB WASM
- Inputs
- Fixed Discord Voice Channel speech recognition
- Outputs
- Experimental singing capabilities
- Engineering
- Shared UnoCSS configuration across projects
- Model catalog in “moeru-ai/inventory”
- Package reorganization across organizations
- Assets
- New character assets including stickers, UI elements, VTuber logos
- Voice line selection functionality
- Live2D modeling for characters “Me” and “ReLU”
- Community Support & Marketing
- Japanese README
- Plausible analytics integration
- Comprehensive documentation
- UI
See you!